OpenClaw / PinchBench Leaderboard
PinchBench is an independent benchmark suite that evaluates LLM capabilities in tool use, function calling, and agentic reasoning. Unlike static Q&A benchmarks, PinchBench tests how well models interact with external tools and APIs — the exact capabilities needed for building production AI agents and automation workflows.
View on GitHubOfficial PinchBench Results
Success rate by model — source: PinchBench authors
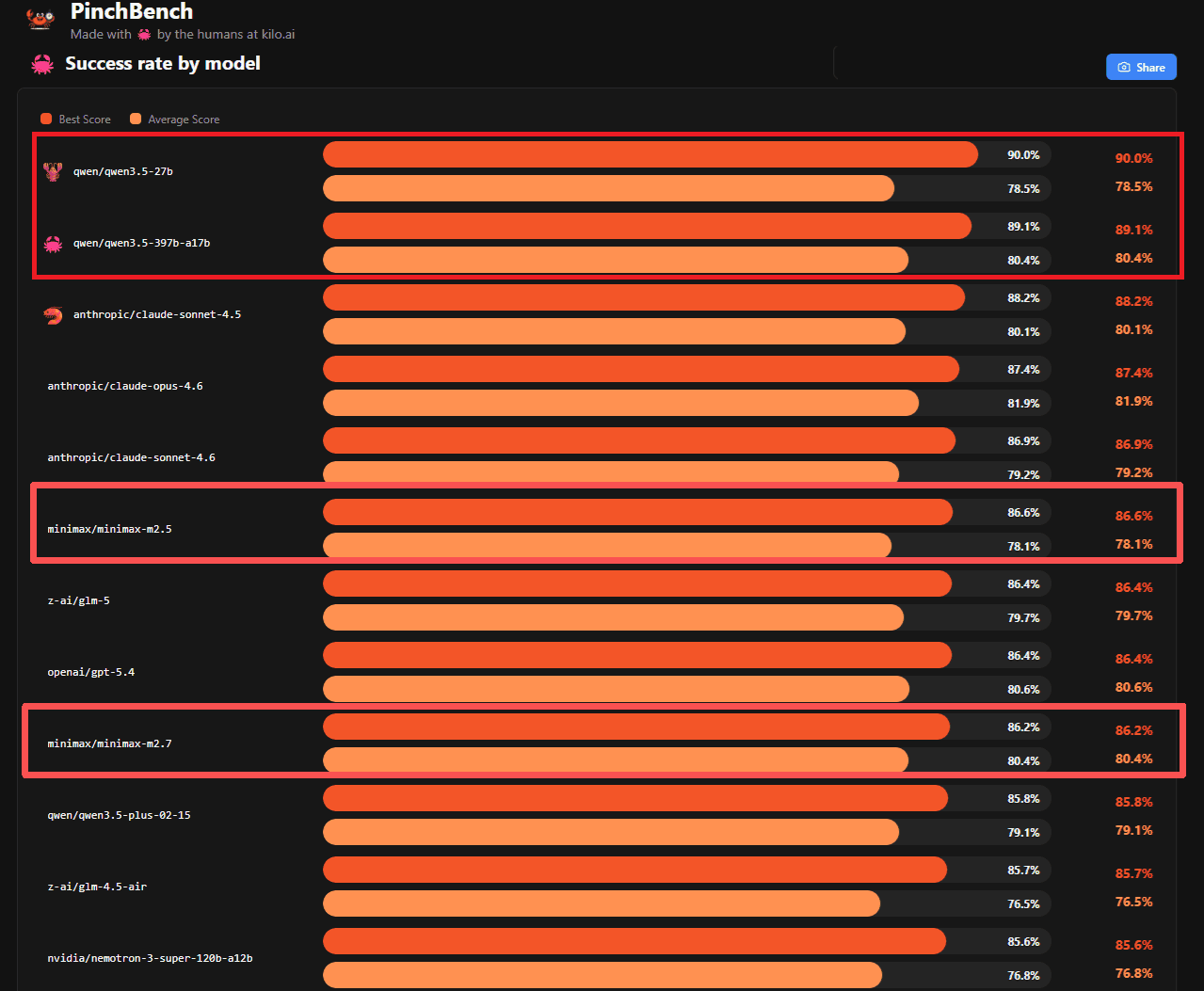
Leaderboard Rankings
Best and average success rates across all PinchBench test categories
| Rank | Model | Provider | Best Score | Avg Score | Performance |
|---|---|---|---|---|---|
| 1 | Qwen 3.5Available | Alibaba | 79.5% | 76.3% | |
| 2 | DeepSeek V4Available | DeepSeek | 79.1% | 75.8% | |
| 3 | Claude Sonnet 4.7Available | Anthropic | 76.5% | 74.2% | |
| 4 | GPT 5.4Available | OpenAI | 76.1% | 73.9% | |
| 5 | GLM 5Available | Zhipu AI | 75.7% | 73.5% | |
| 6 | MiniMax M2.7Available | MiniMax | 75.7% | 73.1% | |
| 7 | Nemotron-3 Super 120BAvailable | NVIDIA | 75.3% | 73% | |
| 8 | Claude Opus 4.2 | Anthropic | 75% | 72.8% | |
| 9 | MiniMax M2.5Available | MiniMax | 74.8% | 72.5% | |
| 10 | Claude Sonnet 4.5 | Anthropic | 74.5% | 71.9% | |
| 11 | GLM-4.5 AirAvailable | Zhipu AI | 74.1% | 71.5% | |
| 12 | DeepSeek V4 LiteAvailable | DeepSeek | 73.8% | 71% | |
| 13 | GPT 5.4 Mini | OpenAI | 73.5% | 70.6% | |
| 14 | Qwen 3.5 TurboAvailable | Alibaba | 73.2% | 70.1% |
Tool Use & Function Calling
PinchBench evaluates how well models handle structured tool calls, function invocations, and API interactions — core capabilities for building AI agents.
Multi-Step Reasoning
Tests include chained reasoning tasks where models must plan, execute, and verify tool calls across multiple steps — simulating real agentic workflows.
Reliability Under Pressure
Measures success rates across hundreds of edge cases including malformed inputs, ambiguous instructions, and complex parameter combinations.
Cost-Performance Sweet Spot
DeepSeek V4 ranks in the top tier with strong cost-performance versus Claude/GPT pricing — making it an excellent choice for high-volume agentic workloads.
Best-Value Models · Deep Discounts
Get Discounted Official API Keys for PinchBench Top Performers
The top-ranking cost-effective models on PinchBench are available here at deeply discounted prices. Qwen (#1), DeepSeek (#2), and more — all official API keys, direct from the providers. Perfect for OpenClaw-style agentic workflows, tool use, and function calling at scale.